Spring知识点
IOC
控制反转,就是创建对象的控制权交给Spring框架,不再由用户使用类的构造方法来new一个对象,IOC的主要实现方式是依赖注入,Spring依赖注入的方式主要有两种,手动注入和自动注入
手动注入(使用配置文件)
a. set方法注入
b. 构造方法注入
自动注入
a. xml (set 和 构造方法)
b. 注解 @Autowired(可以写在1.属性 2.构造方法 3.普通方法)
BeanFactory 和 ApplicationContext的区别
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能:
a. 继承MessageSource,因此支持国际化。
b. 统一的资源文件访问方式。
c. 提供在监听器中注册bean的事件。
d. 同时加载多个配置文件。
e. 载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层。BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
而ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。ApplicationContext启动后预载入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
AOP
AOP:面向切面编程,是面向对象编程(OOP)的一种延续。
OOP 编程思想可以解决大部分的代码重复问题。但是有一些问题是处理不了的。比如在父类 Animal 中的多个方法的相同位置出现了重复的代码,OOP就解决不了。
1 | // 动物父类 |
上面的性能监测代码需要在不同的函数体中进行重复书写,这部分重复的代码,一般统称为横切逻辑代码(多个纵向(顺序)流程中出现的相同子流程代码,一般称之为横切逻辑代码),横切逻辑代码的使用场景很有限,一般是事务控制、权限校验、日志等。
横切逻辑代码存在的问题:
代码重复问题
横切逻辑代码和业务代码混在一起,代码臃肿,不易于维护。
AOP就是用来解决这些问题的,提出横向抽取机制,将横切逻辑代码与业务逻辑代码分离。

代码拆分比较容易,但问题在于如何在不改变原有业务逻辑的情况下,悄无声息的将横向逻辑代码应用到原有的业务逻辑中,达到和原来一样的效果。
通过上面的分析可以发现,AOP 主要用来解决:在不改变原有业务逻辑的情况下,增强横切逻辑代码,根本上解耦合,避免横切逻辑代码重复。
AOP 为什么叫面向切面编程
切 :指的是横切逻辑,原有业务逻辑代码不动,只能操作横切逻辑代码,所以面向横切逻辑
面 :横切逻辑代码往往要影响的是很多个方法,每个方法如同一个点,多个点构成一个面。这里有一个面的概念
AOP使用到的代理模式
静态代理
静态代理代表为AspectJ,所谓静态代理,就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切面)加入到Java字节码中,运行的时候就是增强后的AOP对象。
静态代理. (如果有多个对象要找代理,那么就需要实现很多个对象的代理类,用户体验差;如果被代理的方法过多,每个方法都要增强,代码不整洁)
1 | //原始接口 |
1 | //原始对象 |
1 | //代理对象 |
1 | public class TestProxy{ |
动态代理
Spring AOP是由动态代理实现的。动态代理是指AOP框架不会去修改字节码,而是在运行的过程中生成一个临时的代理对象,这个AOP对象包含了目标对象的全部方法,并且在特定切点处进行了增强处理,并回调原对象的方法(原有的业务逻辑是由原始对象调用的)。主要分为JDK动态代理和Cglib动态代理。
JDK动态代理
核心:InvocationHandler接口和Proxy类
Proxy类利用InvocationHandler动态创建一个符合某一接口的实例(Proxy.newProxyInstance(ClassLoaderloader, Class[] interfaces, InvocationHandler h)), 当代理对象调用真实对象的方法时,会自动的跳转到代理对象关联的handler对象的invoke方法进行调用,动态地将横切逻辑和业务编织在一起。代理类创建真实对象时
//JDK动态代理(创建一个JdkProxy类,用于统一代理)
public class JdkProxy implements InvocationHandler {
private Object bean;
public JdkProxy(Object bean) { //传入原始bean,否则后面调用method.invoke()方法会陷入死循环
this.bean = bean;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if (methodName.equals("wakeup")){
System.out.println("早安~~~");
}else if(methodName.equals("sleep")){
System.out.println("晚安~~~");
}
return method.invoke(bean, args); //使用原始bean调用原有的业务逻辑
}
}
1 | public static void main(String[] args) { |
Cglib动态代理
Spring从5.x开始,开始默认使用Cglib来作为动态代理实现。
Cglib是一个开源项目,它的底层是字节码处理框架ASM,Cglib提供了比jdk更为强大的动态代理。主要相比jdk动态代理的优势有:
- jdk动态代理只能基于接口,代理生成的对象只能赋值给接口变量,而Cglib就不存在这个问题,Cglib是通过生成子类来实现的,代理对象既可以赋值给实现类,又可以赋值给接口。
- Cglib速度比jdk动态代理更快,性能更好。
1 | public class CglibProxy implements MethodInterceptor { |
1 | public static void main(String[] args) { |
Bean的生命周期
- 生成BeanDefinition Spring在启动的时候会进行扫描,找到符合条件的类装载进BeanDefinitionMap中
- 合并BeanDefinition Spring中支持父子BeanDefinition,和Java父子类类似
1 | <bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/> |
这么定义的情况下,child是单例Bean。
1 | <bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/> |
但这种情况下,child是原型Bean。因为child的父BeanDefinition是parent,所以会继承parent上所定义的scope属性。而在根据child来生成Bean对象之前,需要进行BeanDefinition的合并,得到完整的child的BeanDefinition。
加载类 BeanDefinition合并之后,就可以去创建Bean对象了,而创建Bean就必须实例化对象,而实例化就必须先加载当前BeanDefinition所对应的class
实例化 推断构造方法,根据BeanDefinition创建对象
设置对象属性 此处会处理@Autowired(byType)、@Resourse(byName)、@Value等注解,并注入所有的属性。
执行Aware 完成了属性赋值之后,Spring会执行一些回调(回调的作用是让bean具有意识,让它知道自己是一个bean,比如说让它拥有beanName属性,并且可以按照自己的意愿进行修改这些属性),包括:
a. BeanNameAware:回传beanName给bean对象。
b. BeanClassLoaderAware:回传classLoader给bean对象。
c. BeanFactoryAware:回传beanFactory给对象。
初始化前 初始化前调用**BeanPostProcessor.postProcessBeforeInitialization()**(BeanPostProcessor接口中的方法)
初始化
a. 查看当前Bean对象是否实现了InitializingBean接口,如果实现了就调用其afterPropertiesSet()方法
b. 执行BeanDefinition中指定的初始化方法
初始化后 初始化后调用BeanPostProcessor.postProcessAfterInitialization()。可以在这个步骤中,对Bean最终进行处理,Spring中的AOP就是基于初始化后实现的,初始化后返回的对象才是最终的Bean对象
使用Bean 经过流程9后,就可以正式使用Bean了,对于Scope为singleton的Bean,Spring的ioc容器中会缓存一份该bean的实例,而对于scope为prototype的Bean,每次调用都会new一个新的对象,其生命周期交给调用方管理,而不是Spring容器进行管理。
关闭容器 如果Bean实现了DisposableBean接口,则会回调该接口的destroy()方法。如果Bean配置了destroy-method方法,就会执行destroy-method配置的方法。至此整个Bean的生命周期结束。
Spring事务
事务:要么一起成功,要么一起失败
隔离级别:读未提交,读已提交,可重复读,串行化
脏读、不可重复读、幻读
事务丢失:
- 第一类事务丢失(回滚丢失)
对于第一类事务丢失,就是比如A和B同时在执行一个数据,然后B事务已经提交了,然后A事务回滚了,这样B事务的操作就因为A事务回滚而丢失了。(举例,账户上一共有100块钱,然后A事务转出50块,这个时候B事务往账户里转入50块,A事务此时回滚,B事务的操作就因为A事务回滚而丢失了)
- 第二类事务丢失(提交覆盖丢失)
对于第二类事务丢失,也称为覆盖丢失,就是A和B一起执行一个数据,两个同时取到一个数据,然后B事务首先提交,但是A事务接下来又提交,就覆盖了B事务。
编程式事务
主要两种用法:
- 通过PlatformTransactionManager控制事务
1 | @Test |
上述代码主要有5个步骤
a. 定义事务管理器PlatformTransactionManager。事务管理器相当于一个管理员,这个管理员就是用来帮你控制事务的,比如开启事务,提交事务,回滚事务等等。spring中使用PlatformTransactionManager这个接口来表示事务管理器
b. 定义事务属性TransactionDefinition。定义事务属性,比如事务隔离级别、事务超时时间、事务传播方式、是否是只读事务等等。spring中使用TransactionDefinition接口来表示事务的定义信息,有个子类比较常用:DefaultTransactionDefinition。
c. 开启事务。调用事务管理器的getTransaction方法,即可以开启一个事务。这个方法会返回一个TransactionStatus表示事务状态的一个对象,通过TransactionStatus提供的一些方法可以用来控制事务的一些状态,比如事务最终是需要回滚还是需要提交。在getTransaction之后,spring内部会执行一些操作,大致流程如下:
1 | /有一个全局共享的threadLocal对象 resources |
上面代码,将数据源datasource和connection映射起来放在了ThreadLocal中,ThreadLocal大家应该比较熟悉,用于在同一个线程中共享数据;后面我们可以通过resources这个ThreadLocal获取datasource其对应的connection对象。
d. 执行业务操作 我们使用jdbcTemplate插入了2条记录。大家看一下创建JdbcTemplate的代码,需要指定一个datasource
1 | JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource); |
上述代码中两者用到的dataSource是同一个。事务管理器开启事务的时候,会创建一个连接,将datasource和connection映射之后丢在了ThreadLocal中,而JdbcTemplate内部执行db操作的时候,也需要获取连接,JdbcTemplate会以自己内部的datasource去上面的threadlocal中找有没有关联的连接,如果有直接拿来用,若没找到将重新创建一个连接,而此时是可以找到的,那么JdbcTemplate就参与到spring的事务中了。
e. 提交或回滚
- TransactionTemplate
方式1中部分代码是可以重用的,所以spring对其进行了优化,采用模板方法模式就其进行封装,主要省去了提交或者回滚事务的代码。
1 | @Test |
TransactionTemplate,主要有2个方法:
executeWithoutResult:无返回值场景,需传递一个Consumer对象,在accept方法中做业务操作
1 | transactionTemplate.executeWithoutResult(new Consumer<TransactionStatus>() { |
execute:有返回值场景,需要传递一个TransactionCallback对象,在doInTransaction方法中做业务操作
1 | Integer result = transactionTemplate.execute(new TransactionCallback<Integer>() { |
声明式事务
将事务管理代码从业务代码中抽离出来,以声明的方式来实现事务管理。将事务管理作为横切关注点,通过AOP方式模块化。
导入tx约束
1 | xmlns:tx="http://www.springframework.org/schema/tx" |
导入事务管理器依赖
1 | <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> |
事务通知配置
1 | <!--配置事务通知--> |
AOP配置
1 | <!--配置aop织入事务--> |
1 | @Test |
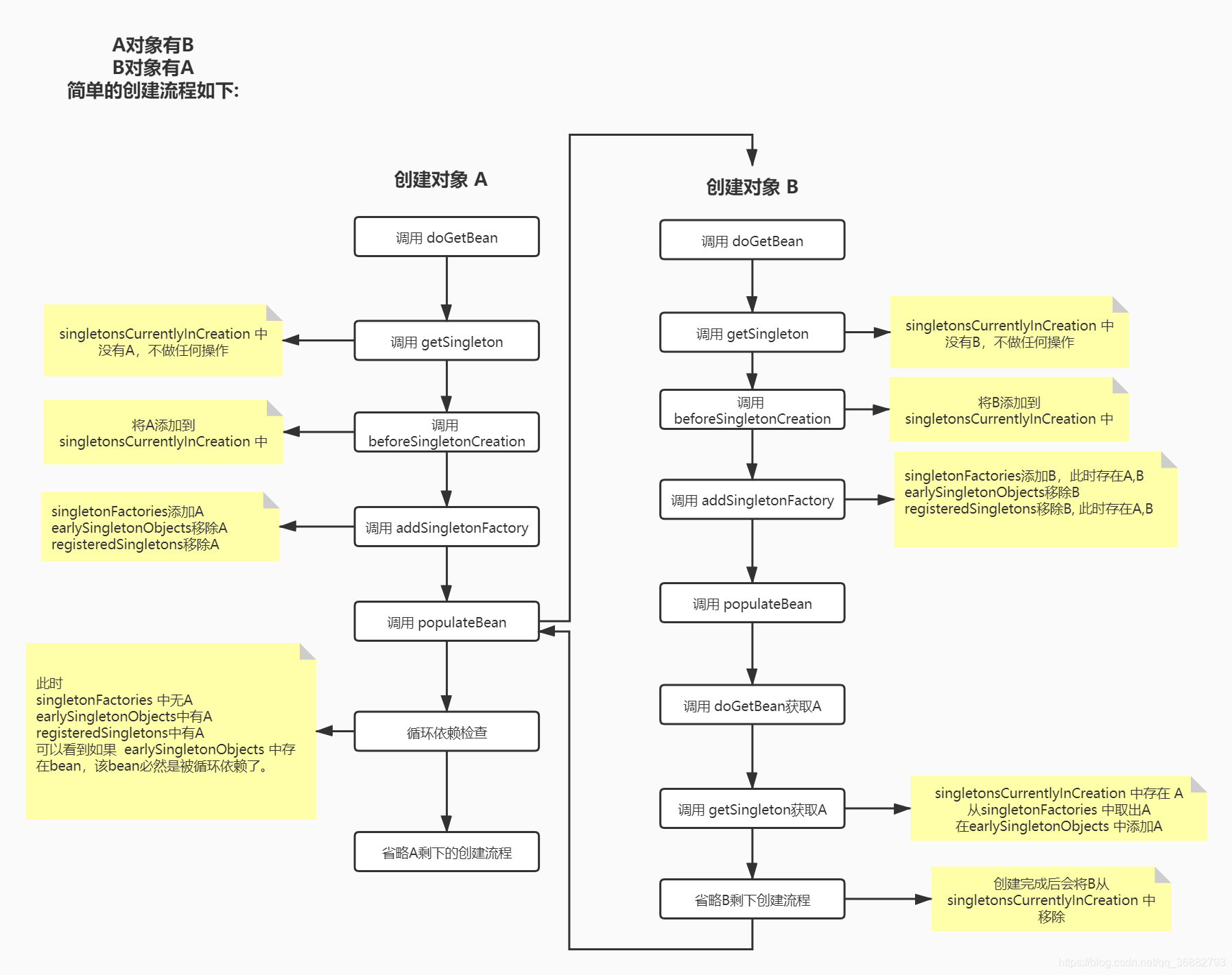
循环依赖与三级缓存
第一级缓存,单例池: SingletonObjects
第二级缓存(earlySingletonObjects):
三级缓存(singletonFactories):Map<beanName : 原始对象> AOP的时候会用到原始对象、beandefinition、beanName,实际上三级缓存的Map存的是一个lambda表达式 Map<beanName : lambda(beanName, bd, 原始对象)>,采用工厂方式(为什么采用工厂方式,是因为有些Bean是需要被代理的(AOP),总不能把代理前的暴露出去那就毫无意义了)
过程(找的顺序,先找一级,再找二级,最后找三级,三级如果有生成二级,删除三级)
- 假设情景A依赖于B,B依赖于A,在创建A的bean时,实例化后,A bean的原始对象构造成ObjectFactory添加三级依赖singletonFactories中,这个ObjectFactory是一个函数式接口,所以支持lambda表达式:**() ->getEarlyBeanReference(beanName, mbd, bean)**
- 属性填充阶段检测到需要依赖B Bean,缓存检测下来发现容器中还没有B Bean,这时创建B Bean,同样将B Bean的Bean工厂添加到三级缓存。
- B Bean实例化后,在属性填充时发现需要A Bean,就从缓存中检查中是否有A Bean,因为在过程1中已经将A Bean的ObjectFactory添加进了三级缓存singletonFactories。所以能够找到A Bean的原始对象。
- 执行三级缓存中的A Bean的原始对象ObjectFactory后,将A Bean的原始对象从三级缓存移到二级缓存,同时移除三级缓存中的对象。
- 三级缓存中的lambda表达式会进行AOP的增强,创建代理类,因此二级缓存earlySingletonObjects存放的有可能是经过AOP增强的代理对象。
- 在AOP增强的时候会用到缓存earlyProxyReferences,这样后面A Bean再自己走到AOP增强的时候会检测是否已经增强。
- 这时B填充完A属性,完成B Bean的创建,便会进入单例池
- A Bean在单例池中取出创建好的Bean完成创建
1 |
|
首先A通过getBean调到doCreateBean(Spring通过getBean方法获取bean),初步实例化即调用createBeanInstance()方法后,属性注入之前进入到下边代码中
1 | public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory |
属性注入之前Spring将Bean包装成一个工厂添加进了三级缓存中,即调用addSingletonFactory()方法。
当A开始属性注入,B开始实例化时,同样会通过getBean,同样会跟A一样属性注入,再次实例化A,此时再次实例化A时,getBean经过getSingleton会从三级缓存中拿出ObjectFactory,调用getObject会拿到A的对象。
到此为止,循环依赖被解决。解决循环依赖后,会在doCreateBean()方法中调用populateBean()方法填充属性,完成对bean的依赖属性进行注入。
即在AbstractBeanFactory类中:
- 通过 getBean(String name)方法、调用doGetBean()方法、在doGetBean()方法内部调用
Object sharedInstance = getSingleton(beanName);代码,在getSingleton()方法中会从三级缓存中拿出ObjectFactory - 通过ObjectFactory单例对象工厂创建的单例对象,放到早期单例对象缓存中即二级缓存earlySingletonObjects,并在三级缓存中移除beanName对应的单例对象工厂

手写Spring框架
扫描过程中每个bean生成一个beandefinition,这个beandefinition保存bean的很多信息,例如bean.class,scope,bean是否懒加载,bean的依赖关系等等,然后将beandefinition放入beandefinitionmap中作为value,key为beanname
围绕bean的生命周期实现了一个简单的Spring框架,简单流程如下:
① 创建一个ApplicationContext类,传入一个config类,该配置类中用@ComponentScan注解声明了扫描路径
1 | @ComponentScan("com.zhouyu.user") |
② 实现ApplicationContext类的基本逻辑:
a. 扫描配置类 scan(configClass) 判断配置类是否有@ComponentScan的注解,如果有取出注解后面标注的值,也就是要扫描的路径。取到扫描路径下的所有文件,然后判断文件中的类是否有@Component注解,如果有,创建一个BeanDefinition对象,设置该类的clazz类、scope值等记录到beanDefinition对象中,并以beanName作为键,beanDefinition作为值存放到beanDefinitionMap中。
1 | private void scan(Class configClass) { |
b. 遍历beanDefinitionMap,判断Scope类型为”singleton”的beandefinition,创建单例Bean实例,对有@Autowired注解标注的类进行依赖注入,对实现Aware接口的类进行设置,对有@Transcational 注解的类将实例对象放到单例池中
1 | for (String beanName : beanDefinitionMap.keySet()) { |
Spring 源码
1.
bean的加载 doGetBean()
我们知道了 Spring 在容器刷新的后期,通过调用AbstractApplicationContext#finishBeanFactoryInitialization 方法来实例化了所有的非惰性bean。在这里面就通过 beanFactory.preInstantiateSingletons(); 调用了一个非常关键的方法 AbstractBeanFactory#getBean(java.lang.String),而其实际上调用的是 AbstractBeanFactory#doGetBean 方法。doGetBean 完成了单例Bean的完整创建过程,包括bean的创建,BeanPostProcessor 的方法调用、init-method等方法的调用、Aware 等接口的实现。
接下来分析AbstractBeanFactory的子类DefaultListableBeanFactory,该子类中重写了doGetBean方法;而且该类继承了DefaultSingletonBeanRegistry接口。
DefaultSingletonBeanRegistry接口中有一些列的集合类型来保存Bean的相关信息。此处指出其中比较重要的几个:
1
2
3
4
5
6
7
8
9
10
11
12/** Cache of singleton objects: bean name to bean instance. */
// 用于保存BeanName和创建bean实例之间的关系,即缓存bean。 beanname -> instance 一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
// 用于保存BeanName和常见bean的工厂之间的关系。beanname-> ObjectFactory 三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
// 也是保存BeanName和创建bean实例之间的关系,与singletonObjects 不同的是,如果一个单例bean被保存在此,则当bean还在创建过程中(比如 A类中有B类属性,当创建A类时发现需要先创建B类,这时候Spring又跑去创建B类,A类就会添加到该集合中,表示正在创建),就可以通过getBean方法获取到了,其目的是用来检测循环引用。 二级缓存
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
/** Set of registered singletons, containing the bean names in registration order. */
// 用来保存当前所有已经注册的bean
private final Set<String> registeredSingletons = new LinkedHashSet<>(256);下面挑出来几个关键缓存集合来描述:
singletonObjects :ConcurrentHashMap。最简单最重要的缓存Map。保存关系是 beanName :bean实例关系。单例的bean在创建完成后都会保存在 singletonObjects 中,后续使用直接从singletonObjects 中获取。
singletonFactories :HashMap。这是为了解决循环依赖问题,用于提前暴露对象,保存形式是 beanName : ObjectFactory<?>。
earlySingletonObjects :HashMap。这也是为了解决循环依赖问题。和 singletonFactories 互斥。因为 singletonFactories 保存的是 ObjectFactory。而earlySingletonObjects 个人认为是 singletonFactories 更进一步的缓存,保存的是 ObjectFactory#getObject的结果。
registeredSingletons :LinkedHashSet,用于保存注册过的beanName